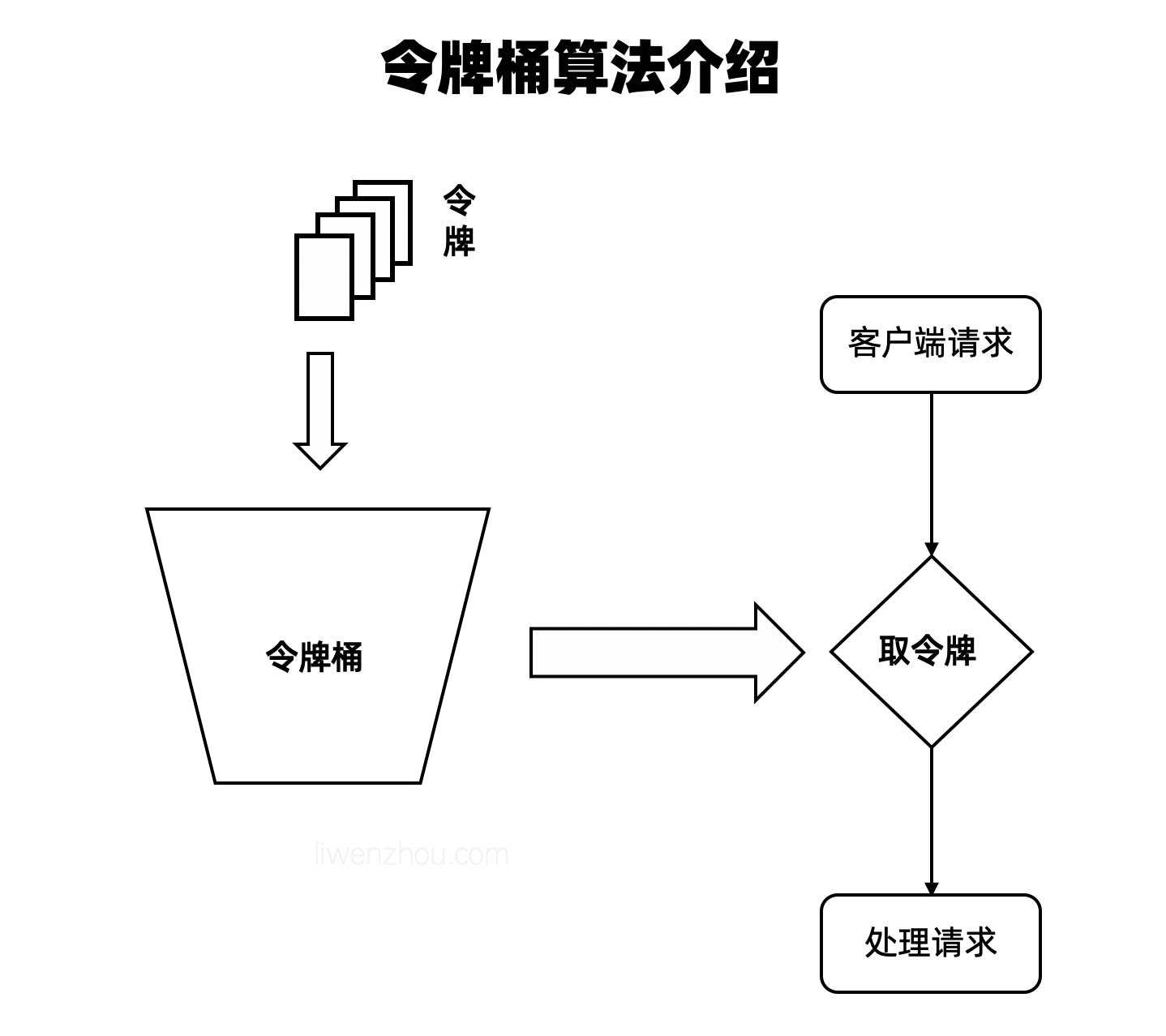
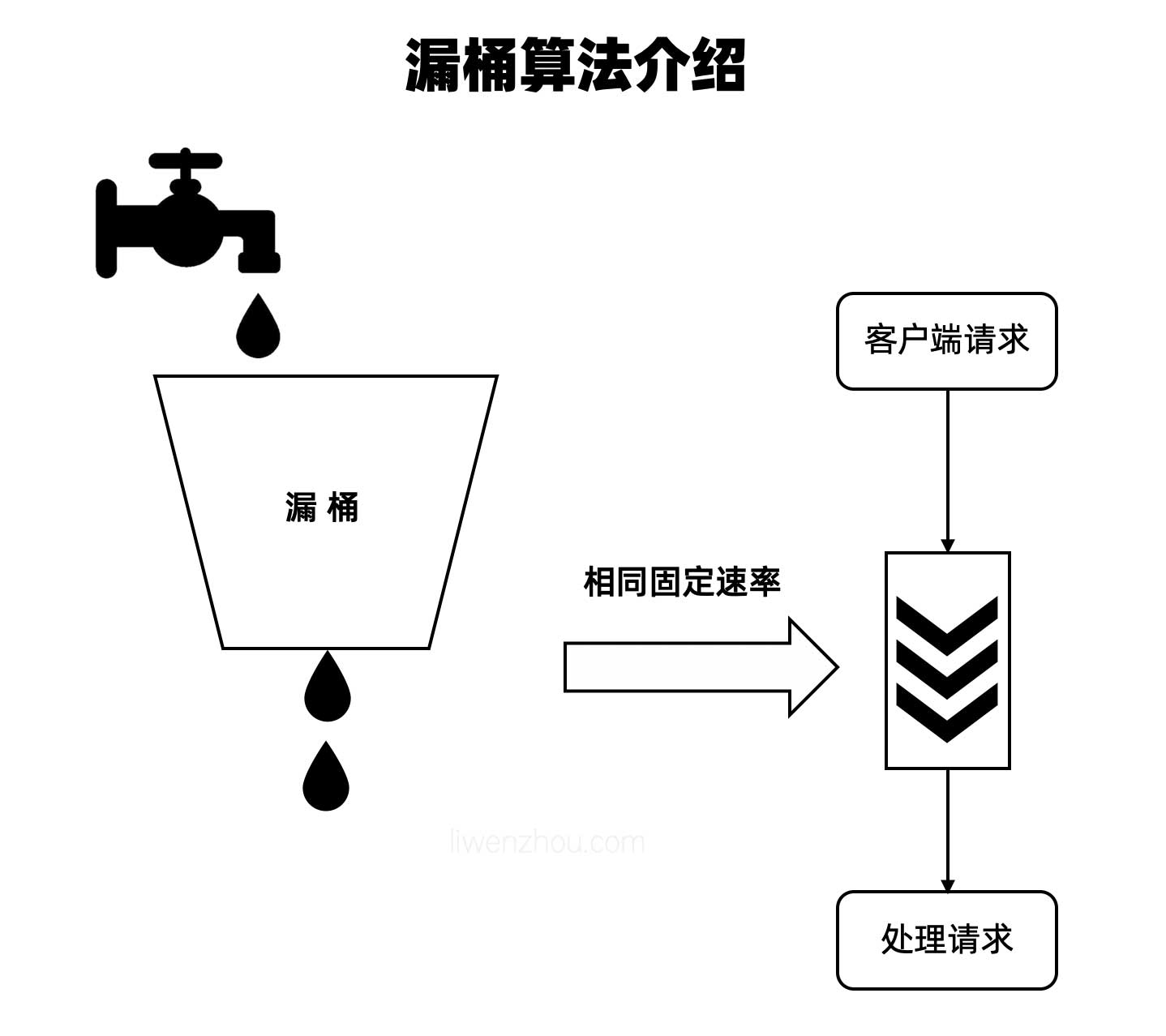
I/O多路复用的含义
IO多路复用(I/O Multiplexing)是指在一个线程或进程中,通过某种机制同时处理多个I/O操作的技术。它通常用于高并发的网络编程中,尤其是在处理大量客户端请求时,能够有效提高系统的性能和响应速度。
在传统的阻塞I/O模型中,操作系统为每个I/O请求分配一个线程或进程,每个线程都会等待I/O操作完成,这样在高并发的情况下就会造成大量的资源浪费。而IO多路复用通过使单个线程能够同时管理多个I/O操作,避免了创建大量线程,从而提高了系统的效率。
常见的IO多路复用技术:
select:
select是最早的IO多路复用机制,允许一个线程监视多个文件描述符(通常是网络连接),并在其中任何一个文件描述符就绪时通知应用程序进行处理。
限制:每次调用时最多只能监视1024个文件描述符(操作系统对select的限制),而且效率较低。
poll:
poll与select类似,但是它不受文件描述符数量的限制,可以支持更多的文件描述符。
但是,poll依然存在遍历所有文件描述符的性能瓶颈,特别是在处理大量连接时,性能较低。
epoll(Linux特有):
epoll是Linux下的一种高效IO多路复用机制,它通过事件驱动的方式,只关心那些发生了事件的文件描述符,避免了遍历所有文件描述符的开销。
支持水平触发(Level-Triggered, LT)和边缘触发(Edge-Triggered, ET)两种模式,能够有效提高高并发情况下的性能。
kqueue(BSD和macOS特有):
kqueue是BSD系统上的IO多路复用机制,功能与epoll类似,也支持高效的事件通知机制。
应用场景
- 高并发网络编程(Redis,Nginx,数据库连接池等等);
- 大量并发I/O操作的场景,如处理多个客户端请求、文件传输等;
和HTTP协议多路复用的区别
概念:
I/O多路复用是操作系统的技术,允许在一个线程或进程中同时处理多个 I/O 操作(通常是网络连接)。
HTTP/2多路复用 是一种协议机制,允许多个 HTTP 请求和响应在同一个 TCP 连接上并行传输,减少了因多次建立连接而带来的开销。
目的:
I/O多路复用主要目的是提高高并发场景下的资源利用效率,减少线程开销。
HTTP/2多路复用主要目的是减少 HTTP 协议中多个请求/响应之间的延迟,提高带宽利用率。
工作原理:
I/O多路复用指的是操作系统提供的机制,允许一个线程或进程同时监视多个 I/O 操作(通常是文件描述符、网络套接字等),操作系统提供了 select、poll、epoll 等系统调用,允许一个线程同时等待多个文件描述符上的事件(例如,网络数据是否可读、是否可写)。当其中某个文件描述符上的事件发生时,操作系统会通知应用程序,应用程序随后处理该事件。
HTTP/2 的多路复用是指在一个 TCP 连接上同时并行地发送多个请求和响应。不同于 HTTP/1.x 中的每个请求和响应必须各自占用一个独立的 TCP 连接,HTTP/2 的多路复用允许多个 HTTP 请求和响应在同一个连接上交替进行,不需要等待前一个请求完成后才能开始下一个请求。
HTTP/2 使用 二进制分帧(binary framing) 的方式,将请求和响应分解为多个小的帧(frame),然后将这些帧通过一个连接交错发送。每个请求和响应都会被分配一个唯一的流标识符(stream identifier),可以在同一个连接中并发地发送多个流,而不需要等待其他流的完成。
这种机制是通过使用一个 流(stream)来标识不同的请求和响应,每个流包含多个 帧(frame),这些帧可以在网络上交替传输。因为 HTTP/2 只使用一个 TCP 连接,所以可以有效避免 HTTP/1.x 中“头阻塞”问题(head-of-line blocking)。
I/O 多路复用与 Go channel
Go 的 channel 在底层也利用了 I/O 多路复用 的概念,尤其是在实现高并发、协程间通信时。虽然 Go 的 channel 并不是直接操作文件描述符或网络连接,但 Go 的 调度器(Goroutine Scheduler) 和 channel 的实现 使用了类似于 I/O 多路复用的技术来高效地处理大量并发的任务。
Go 中的 channel 实现并不直接使用操作系统的 I/O 多路复用机制(如 epoll 或 select),但它与这些技术在概念上非常相似,具体来说:
select语句:Go 的select语句允许一个 Goroutine 在多个channel上进行阻塞操作,直到某个channel就绪。这种机制类似于操作系统中的 I/O 多路复用,允许程序在多个 I/O 操作之间进行选择,直到其中一个操作完成。1
2
3
4
5
6
7
8
9
10select {
case msg1 := <-ch1:
// 处理 ch1 的消息
case msg2 := <-ch2:
// 处理 ch2 的消息
case ch3 <- 3:
// 向 ch3 发送数据
default:
// 没有任何 case 就绪时执行
}这里的
select语句会阻塞当前 Goroutine,直到其中一个channel的操作(发送或接收)完成。它会在多个channel上等待,类似于操作系统如何在多个文件描述符上等待事件。调度器(Scheduler):Go 的调度器(Goroutine Scheduler)也使用了类似于 I/O 多路复用的事件驱动机制来处理成千上万的 Goroutines。在高并发场景下,Go 调度器能够在单个线程上调度数以千计的 Goroutines,这得益于 Go 对 Goroutine 的高效管理和调度。每个 Goroutine 的状态变化(如从阻塞到就绪)都会触发调度器的处理,这类似于 I/O 多路复用在操作系统中对事件的监听和分发。
Go channel 底层实现
Go 的 channel 是由运行时(runtime)实现的,它与底层的调度器和事件循环机制密切相关。虽然 channel 的实现并不直接操作文件描述符,但它使用了类似的技术来避免大量的阻塞和等待。具体而言,Go 会将阻塞的 Goroutines 放入 等待队列,并通过事件通知机制(即调度器)唤醒相应的 Goroutine。
当你在多个 channel 上使用 select 语句时,Go 调度器通过类似于 I/O 多路复用的机制等待 channel 上的事件发生(例如,某个 channel 变为可读或可写),然后调度相应的 Goroutine 执行。这种处理方式类似于 I/O 多路复用在网络编程中的应用。
虽然 Go 的 channel 实现本身并不直接依赖于操作系统级别的 I/O 多路复用(如 epoll、select 等),但 Go 的调度器和 channel 的实现使用了类似的事件驱动模型。在多个 channel 上等待事件时,Go 的调度器会高效地管理多个 Goroutines,并且避免了传统的阻塞模型所带来的性能问题。因此,Go 中的 channel 和 select 语句在并发控制上使用了与 I/O 多路复用相似的思想,以实现高效的协程调度和通信。