GPU和CPU的区别
CPU架构设计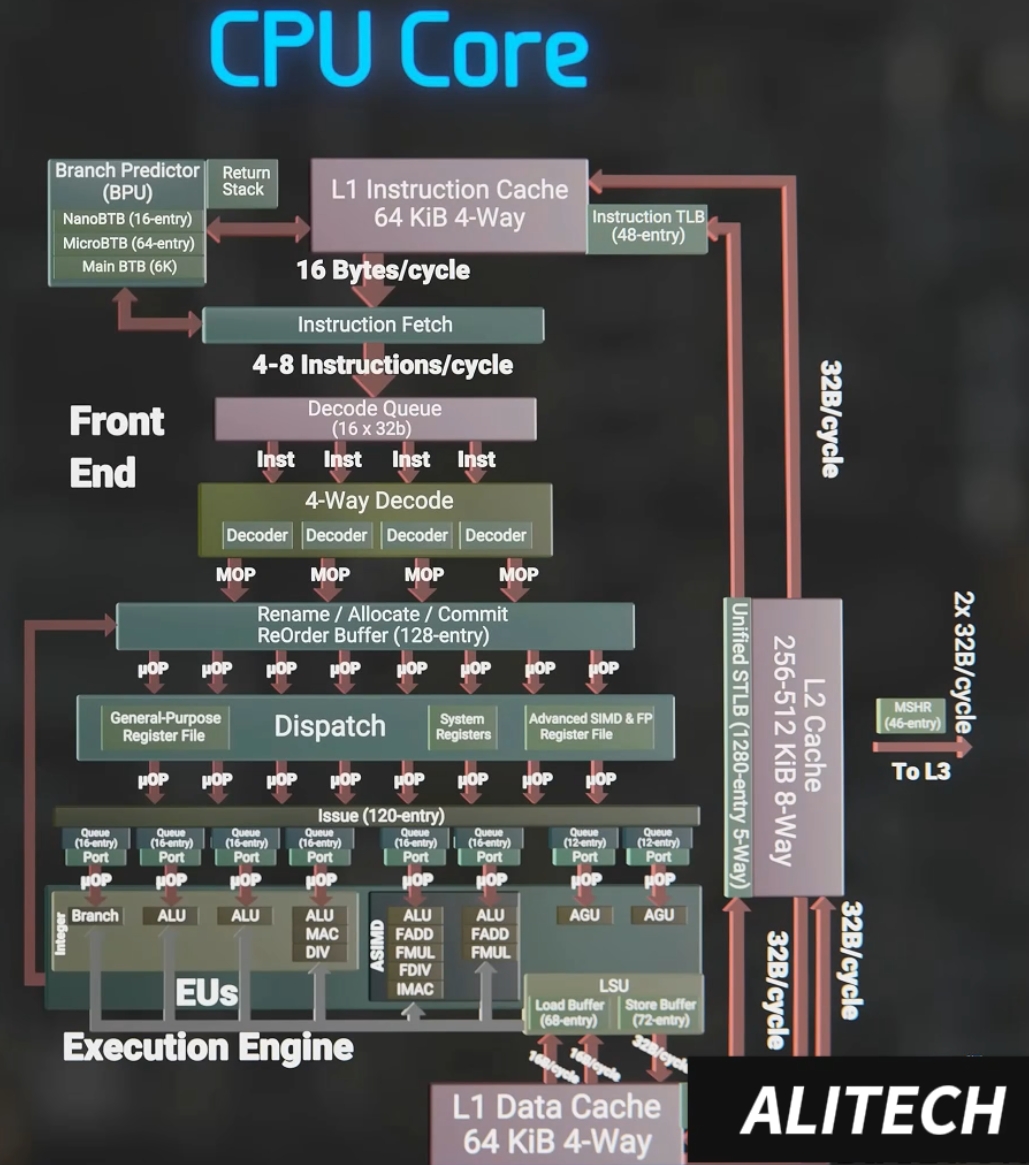
CPU核心参数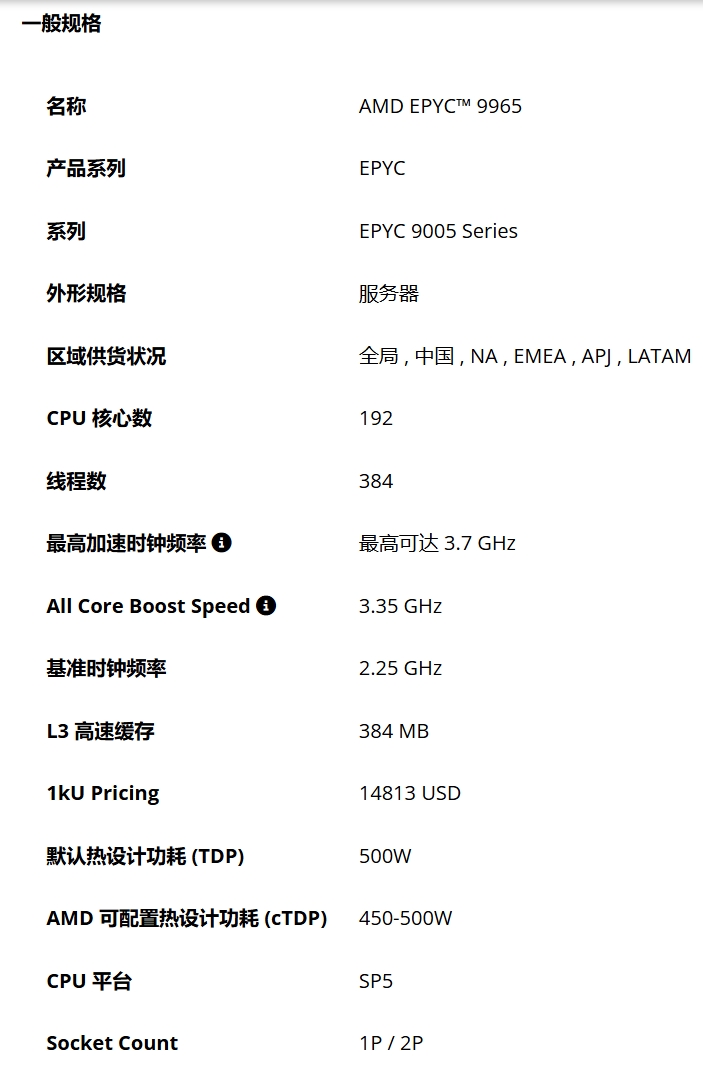
GPU架构设计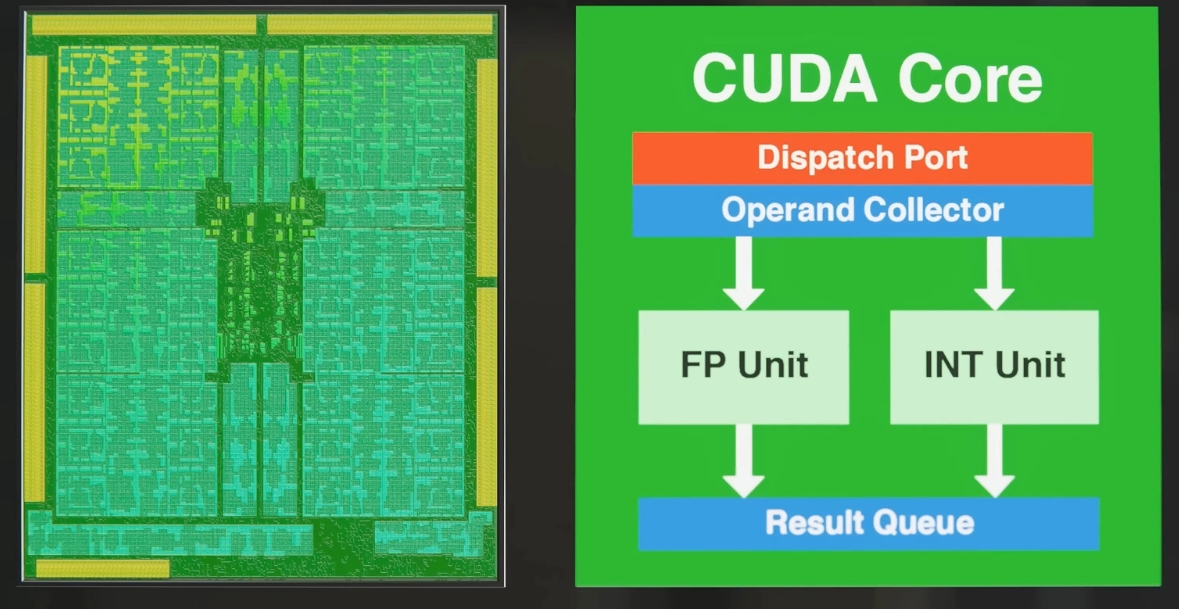
GPU核心参数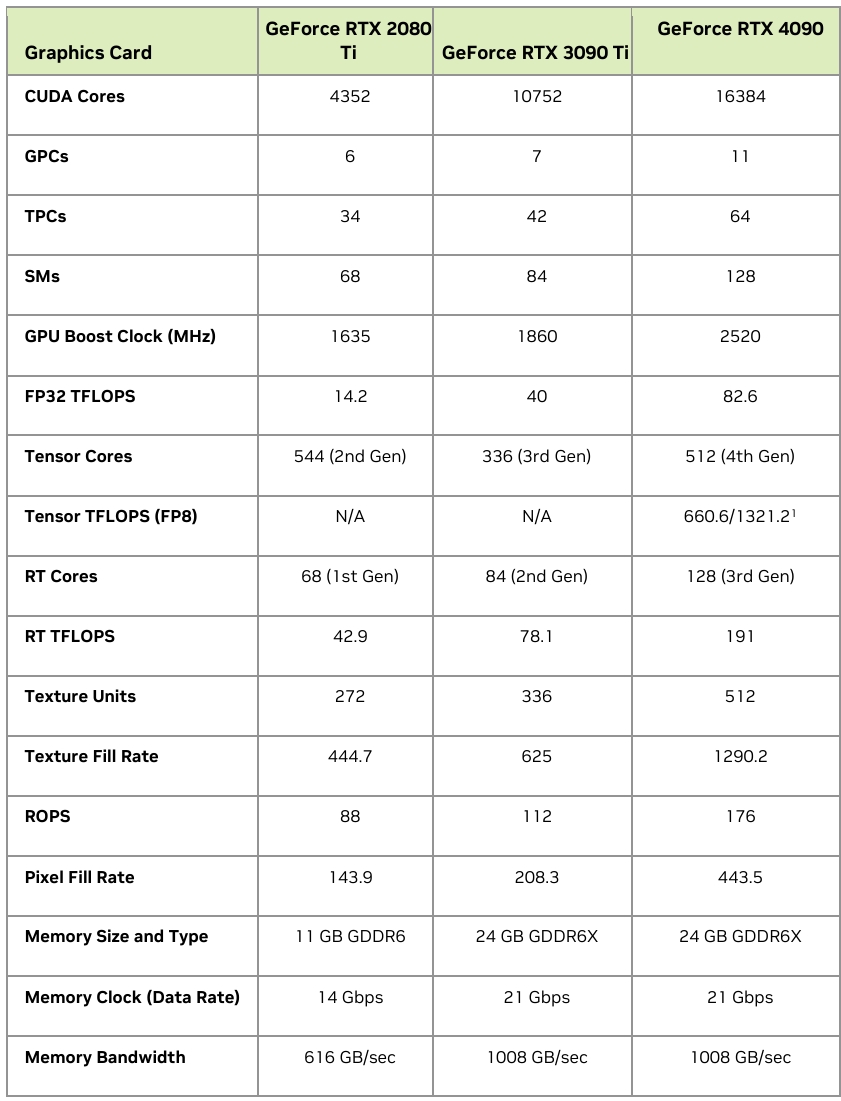
在CPU的架构中包含多级缓存,各种复杂操作指令集,CPU的架构设计是为了支持复杂的逻辑运算,每个核心都是完整通用的处理器单元,且其工作模式实际上是串行执行任务的,GPU的架构从设计之初就是专门用于处理图像和视频等图形数据,具有大量的流处理器和着色器,且其工作模式是并行执行任务的,从规格也可以看出除了核心数外同期的GPU比CPU有更高的时钟频率和内存带宽。
总结下来GPU和CPU的主要区别在以下几点:
- 并行计算能力:
GPU:GPU设计为大规模的并行计算,具有数千个小型处理核心,这些核心能够同时执行大量的计算任务。深度学习中的许多计算(如矩阵乘法、卷积运算等)都可以高度并行化。GPU能够同时处理多个数据流(例如,多个神经元的计算),从而大大提高了训练效率。
CPU:CPU一般只有少数几个(通常为4到16个)强大的核心,适合处理顺序执行的任务。CPU适合执行需要复杂决策和高频任务的应用,但在深度学习中的大规模矩阵计算、卷积等任务上,其并行能力远逊色于GPU。 - 内存带宽:
GPU:GPU通常配备更宽的内存带宽,允许其快速访问和处理大规模的数据集。例如,现代GPU如NVIDIA的A100、V100、H100等,具有高达1TB/s的内存带宽。这使得GPU在处理大规模数据集时能够更快地读取和写入数据,从而提高了训练速度。
CPU:虽然CPU的内存带宽也在不断提高,但通常远低于GPU。CPU的内存带宽有限,这使得它在处理深度学习中的大规模数据时,可能成为瓶颈,尤其是对于需要大量数据交换的神经网络模型(如大规模图像、视频处理等)。
适合GPU计算的场景
- 图形渲染和计算机视觉
图形渲染:GPU最初的设计目的是加速图形渲染,特别是3D图形。GPU在计算机图形学中通过执行大量并行的图形计算(如光照、阴影、纹理映射等)来加速渲染过程。
应用:视频游戏、虚拟现实(VR)、增强现实(AR)、3D建模和动画制作。
计算机视觉:GPU可以加速图像处理、目标检测、图像分割、面部识别、自动驾驶汽车中的视觉系统等任务。
应用:安防监控、医学影像分析、自动驾驶、工业视觉检测。 - 大规模矩阵计算
GPU:深度学习中的核心任务(如反向传播中的梯度计算和前向传播中的矩阵乘法)是矩阵计算密集型的。GPU特别适合这类任务,因为它能通过并行计算同时处理矩阵中的多个元素。NVIDIA的GPU通过CUDA等库进一步优化了这些运算,使得在训练深度学习模型时,GPU能够极大提升计算效率。
CPU:虽然CPU也能进行矩阵计算,但由于缺乏大规模的并行处理能力,CPU在执行大规模矩阵计算时远远不如GPU高效。 - 自然语言处理(NLP)
加速NLP任务:GPU在处理大规模文本数据、训练和推理自然语言处理模型(如Transformer、BERT、GPT等)时表现出色。NLP模型通常需要大量的计算资源来处理文本序列,GPU能够显著加速这些计算。
应用:机器翻译、语音识别、聊天机器人、情感分析、文本生成。 - 医学影像处理
CT、MRI图像处理:医学影像处理中常常需要进行大规模的数据分析和图像处理,GPU能够加速图像重建、分割、识别等任务。
自动诊断:Nvidia的GPU通过CUDA可以加速基于深度学习的自动化诊断系统,如利用卷积神经网络(CNN)进行肿瘤检测、器官分割等任务。
深度学习和神经网络
深度学习和神经网络是紧密相关的概念,但它们并不完全相同。以下是它们之间的关系及区别:
1. 神经网络(Neural Networks)
神经网络是模仿生物神经系统的计算模型,尤其是大脑神经元之间的连接结构。在人工智能领域,神经网络被用来进行数据处理和模式识别。
基本概念:
- 神经网络(Neural Network):由一组互相连接的节点(即神经元)组成,这些神经元通过权重相连。神经网络可以进行监督学习和非监督学习,用于完成分类、回归等任务。
- 层次结构:神经网络通常包含输入层、隐藏层和输出层。每一层包含若干神经元(节点),每个神经元接受前一层的输出,并通过激活函数处理后传递给下一层。
- 激活函数:通常使用如ReLU、Sigmoid、Tanh等激活函数来增加网络的非线性能力。
传统神经网络(浅层神经网络):
- 神经网络最初并不深,通常只有一层或两层隐藏层(即浅层神经网络)。这些浅层网络对于一些简单的任务(如线性可分问题)效果良好。
- 不足:浅层神经网络无法有效地处理复杂、高维的数据和任务(如图像识别、自然语言处理等),并且存在梯度消失和梯度爆炸的问题。
2. 深度学习
深度学习是神经网络的一种拓展,它指的是具有多个隐藏层(即深层结构)的神经网络模型。深度学习的“深度”通常指的是网络中有多个隐藏层,而这些层次使得模型能够自动学习和提取数据的高级特征。
基本概念:
- 深度神经网络:深度学习中的神经网络通常包含很多隐藏层,这些层使得模型能够逐步提取数据的高层次特征。
- 多层学习:每一层可以从前一层的输出中学习到更复杂的特征。比如,在图像识别中,浅层可以学习边缘和简单形状,中间层可以学习纹理和局部结构,深层可以学习复杂的对象或场景。
- 反向传播算法:深度学习模型通常使用反向传播(backpropagation)和梯度下降等优化方法来训练网络,使得模型能够逐渐减少损失函数的值,找到最佳的权重参数。
主要特点:
- 深度结构:深度学习网络有多个隐藏层,通常包含上百或上千个神经元。
- 自我特征提取:深度学习能够自动从原始数据中提取特征,而无需人工手动设计特征。这使得深度学习在处理复杂任务(如语音识别、自然语言处理、图像识别等)时表现优越。
- 大数据和计算资源:深度学习通常需要大量的训练数据和强大的计算能力(如GPU)来训练深度神经网络。
3. 深度学习和神经网络的关系
- 深度学习是神经网络的一个子集:深度学习本质上是通过深层神经网络(DNN)来解决更复杂的任务。它是神经网络的一种扩展或进阶版本,强调使用深度(多层)的结构来提取数据中的高级特征。
- 神经网络可以是浅层的:而深度学习网络通常都是深层的神经网络。浅层神经网络和深度学习之间的主要区别在于网络的深度(即隐藏层的数量)。
- 深度学习模型的优势:深度学习能够从大量的复杂数据中学习到有用的表示(特征),并且在很多任务上超越了传统的浅层神经网络,尤其是在图像、语音、文本等领域。
4. 神经网络的种类与深度学习的相关性
深度学习使用的神经网络架构通常比传统的神经网络更加复杂和深层。常见的深度学习网络架构包括:
- 卷积神经网络(CNN):专门用于处理图像数据,通过卷积层提取图像中的局部特征,广泛应用于图像分类、目标检测等任务。
- 循环神经网络(RNN):适用于处理序列数据,能够处理时间依赖性较强的问题,如语音识别、语言建模等。
- 长短时记忆网络(LSTM):RNN的一种变种,能够更好地捕捉长时间序列中的依赖关系。
- 变换器网络(Transformer):主要用于自然语言处理(NLP)任务,特别是语言模型(如BERT、GPT)。它基于自注意力机制,可以并行化训练并处理长序列数据。
5. 深度学习的核心优势
- 自动特征学习:深度学习能够自动从原始数据中学习出特征,而不需要手动设计特征。这对于复杂的任务(如图像分类、语音识别等)非常有利。
- 高维数据处理:深度神经网络能有效处理高维、复杂的数据,如图像、音频和文本等。
- 性能提升:随着数据量和计算能力的增加,深度学习在许多任务上都表现出了比传统机器学习方法更优的性能。
6. 总结
- 神经网络是深度学习的基础,指的是由多个神经元连接组成的计算模型。传统神经网络通常是“浅层”的,只有少量的隐藏层。
- 深度学习是利用深层神经网络(即具有多个隐藏层的神经网络)来自动学习数据的高级特征。深度学习通过多个层次的非线性映射,将复杂的输入数据转化为有用的表示,在许多任务中取得了突破性进展。
简而言之,深度学习是基于神经网络的一种进阶应用,它通过深层次结构和大规模数据的处理,解决了更复杂、更抽象的问题。