1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
|
'''
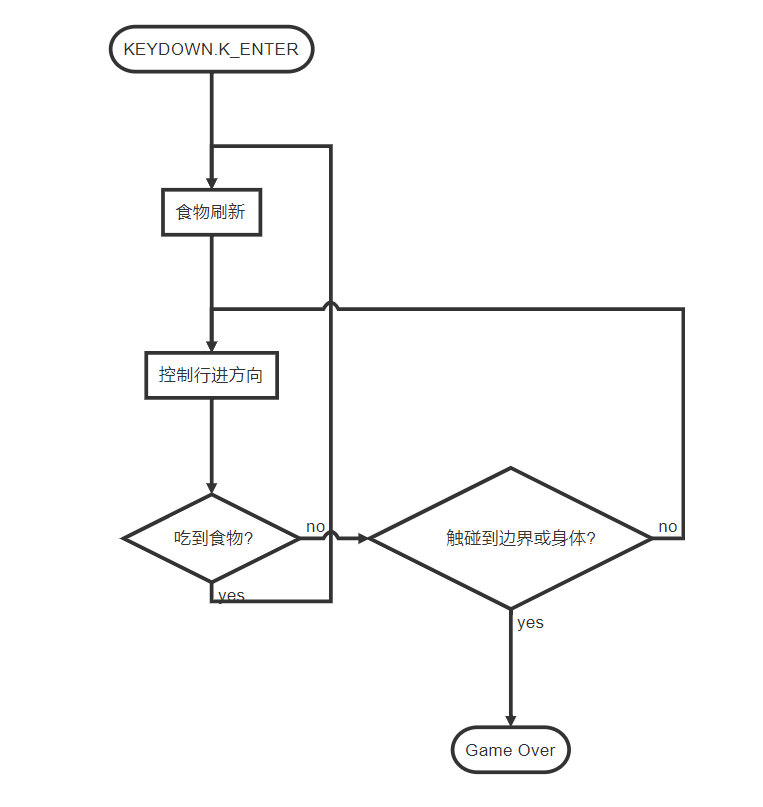
游戏玩法:回车开始游戏;空格暂停游戏/继续游戏;方向键/wsad控制小蛇走向
'''
'''
思路:用列表存储蛇的身体;用浅色表示身体,深色背景将身体凸显出来;
蛇的移动:仔细观察,是:身体除头和尾不动、尾部消失,头部增加,所以,新添加的元素放在列表头部、删除尾部元素;
游戏结束判定策略:超出边界;触碰到自己的身体:蛇前进的下一格子为身体的一部分(即在列表中)。
'''
import random
import sys
import time
import pygame
from pygame.locals import *
from collections import deque
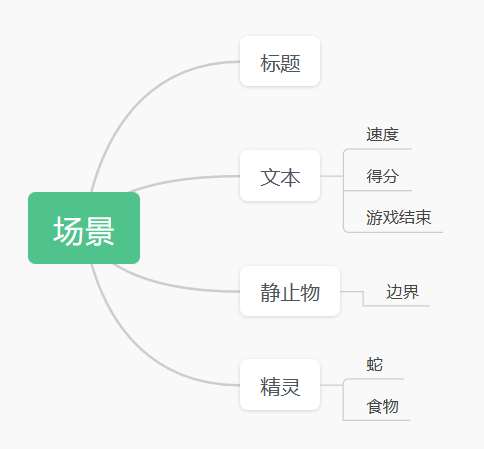
Screen_Height=720
Screen_Width=1280
Size=20
Line_Width=1
Area_x=(0,Screen_Width//Size-1)
Area_y=(2,Screen_Height//Size-1)
Food_Style_List=[(10,(255,100,100)),(20,(100,255,100)),(30,(100,100,255))]
Light=(100,100,100)
Dark=(200,200,200)
Black=(0,0,0)
Red=(200,30,30)
Back_Ground=(40,40,60)
def Print_Txt(screen,font,x,y,text,fcolor=(255,255,255)):
Text=font.render(text,True,fcolor)
screen.blit(Text,(x,y))
def init_snake():
snake=deque()
snake.append((2,Area_y[0]))
snake.append((1,Area_y[0]))
snake.append((0,Area_y[0]))
return snake
def Creat_Food(snake):
'''
注:randint 产生的随机数区间是包含左右极限的,
也就是说左右都是闭区间的[1, n],能取到1和n。
而 randrange 产生的随机数区间只包含左极限,
也就是左闭右开的[1, n),1能取到,而n取不到。randint
产生的随机数是在指定的某个区间内的一个值,
而 randrange 产生的随机数可以设定一个步长,也就是一个间隔。
'''
food_x=random.randint(Area_x[0],Area_x[1])
food_y=random.randint(Area_y[0],Area_y[1])
while(food_x,food_y)in snake:
food_x = random.randint(Area_x[0], Area_x[1])
food_y = random.randint(Area_y[[0], Area_y[1]])
return food_x,food_y
def Food_Style():
return Food_Style_List[random.randint(0,2)]
def main():
pygame.init()
screen=pygame.display.set_mode((Screen_Width,Screen_Height))
pygame.display.set_caption('贪吃蛇')
font1=pygame.font.SysFont('SimHei',24)
font2 = pygame.font.SysFont(None, 72)
fwidth, fheight = font2.size('GAME OVER')
b=True
snake=init_snake()
food=Creat_Food(snake)
food_style=Food_Style()
pos=(1,0)
game_over=True
game_start=False
score=0
orispeed=0.3
speed=orispeed
last_move_time=None
pause=False
while True:
for event in pygame.event.get():
if event.type==QUIT:
sys.exit()
elif event.type==KEYDOWN:
if event.key==K_RETURN:
if game_over:
game_start=True
game_over=False
b=True
snake=init_snake()
food=Creat_Food(snake)
food_style=Food_Style()
pos=(1,0)
score=0
last_move_time=time.time()
elif event.key==K_SPACE:
if not game_over:
pause=not pause
elif event.key in (K_UP,K_w):
if b and not pos[1]:
pos=(0,-1)
b=False
elif event.key in (K_DOWN,K_s):
if b and not pos[1]:
pos = (0, 1)
b = False
elif event.key in (K_LEFT,K_a):
if b and not pos[0]:
pos = (-1, 0)
b = False
elif event.key in (K_RIGHT,K_d):
if b and not pos[0]:
pos = (1, 0)
b = False
screen.fill(Back_Ground)
for x in range(Size, Screen_Width, Size):
pygame.draw.line(screen, Black, (x, Area_y[0] * Size), (x, Screen_Height), Line_Width)
for y in range(Area_y[0] * Size, Screen_Height, Size):
pygame.draw.line(screen, Black, (0, y), (Screen_Width, y), Line_Width)
if not game_over:
curTime=time.time()
if curTime-last_move_time>speed:
if not pause:
b=True
last_move_time=curTime
next_s = (snake[0][0] + pos[0], snake[0][1] + pos[1])
if next_s==food:
snake.appendleft(next_s)
score+=food_style[0]
speed = orispeed - 0.03 * (score // 100)
food = Creat_Food(snake)
food_style = Food_Style()
else:
if Area_x[0]<=next_s[0]<=Area_x[1] and Area_y[0]<=next_s[1]<=Area_y[1] and next_s not in snake:
snake.appendleft(next_s)
snake.pop()
else :
game_over=True
if not game_over:
'''
rect(Surface,color,Rect,width=0)
第一个参数指定矩形绘制到哪个Surface对象上
第二个参数指定颜色
第三个参数指定矩形的范围(left,top,width,height)
第四个参数指定矩形边框的大小(0表示填充矩形)
例如绘制三个矩形:
pygame.draw.rect(screen, BLACK, (50, 50, 150, 50), 0)
pygame.draw.rect(screen, BLACK, (250, 50, 150, 50), 1)
pygame.draw.rect(screen, BLACK, (450, 50, 150, 50), 10)
'''
pygame.draw.rect(screen, food_style[1], (food[0] * Size, food[1] * Size, Size, Size), 0)
for s in snake:
pygame.draw.rect(screen, Dark, (s[0] * Size + Line_Width, s[1] * Size + Line_Width,
Size - Line_Width * 2, Size - Line_Width * 2), 0)
Print_Txt(screen, font1, 30, 7, f'速度: {score // 100}')
Print_Txt(screen, font1, 450, 7, f'得分: {score}')
if game_over:
if game_start:
Print_Txt(screen, font2, (Screen_Width - fwidth) // 2, (Screen_Height - fheight) // 2, 'GAME OVER',Red)
pygame.display.update()
if __name__=='__main__':
main()
|